

@higo1974j ありがとうございます!
昨日から熱が下がらないので病院行ったらコロナ陽性だったorz
松尾研のLLM使うサンプルプログラム、色々削ったらトゥートできるくらい短くなった。
pythonでtorchとtransformesセットアップすれば最新のLLMが自宅で動かせるとか凄い時代た。
import torch, transformers
u="matsuo-lab/weblab-10b-instruction-sft"
m=transformers.AutoModelForCausalLM.from_pretrained(u,torch_dtype=torch.float16)
t=transformers.AutoTokenizer.from_pretrained(u,use_fast=False)
p=transformers.pipeline("text-generation",model=m,tokenizer=t,device=0)
print(p("プロンプト",max_length=160,pad_token_id=t.pad_token_id)[0]['generated_text'])
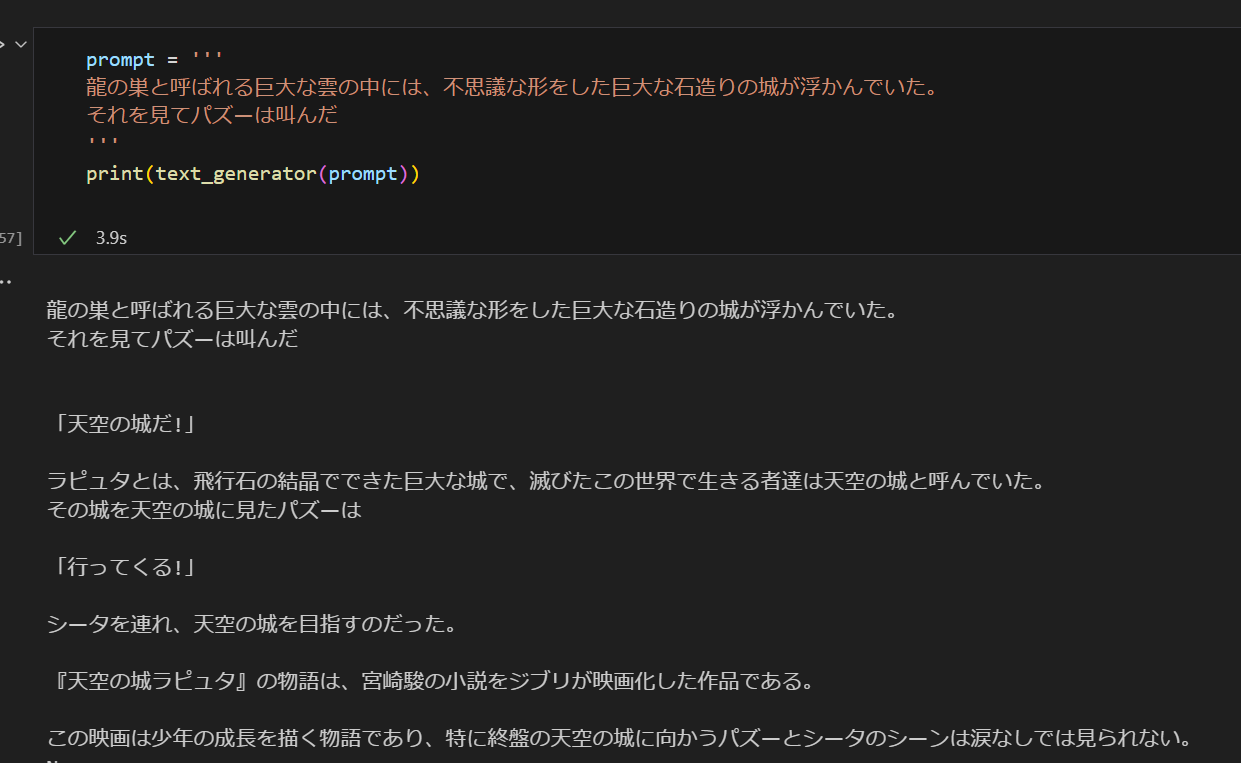
松尾研のLLMを試してみたところ、Lineよりかなり自然な会話が生成できる模様です。
ただLineの方が面白い会話になりやすい傾向があるかも。
家鴨
さんがブースト


日本特化LLMの流れがすごい。今度は松尾研の10 billion
https://x.com/matsuo_lab/status/1692343390858600655?s=12&t=o8BynjbGKRWxQB_mh1VAhQ
確かに、生成では無く画像入力で日本語の応答を生成できるモデルですね。
日本語ネイティブでも無くベースは英語のInstrructBLIPでした。
ちゃんと記事読まずに脊髄反射するとフェイクニュース作ってしまうので気を付けねば、、、
日本語ネイティブな画像生成AI来た。
画像に関する質問も日本語で返ってくるのと使い道色々ありそう。
https://ja.stability.ai/blog/japanese-instructblip-alpha
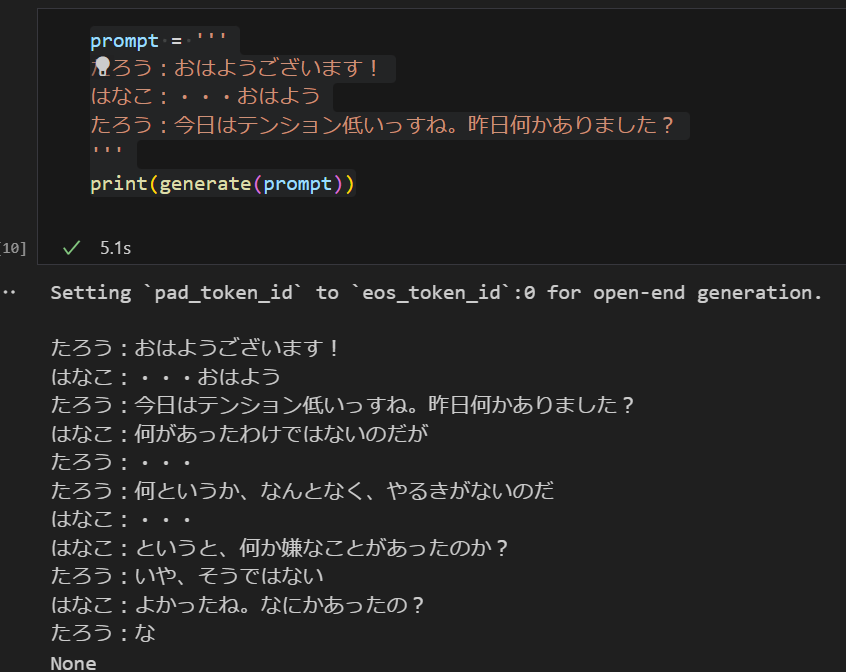
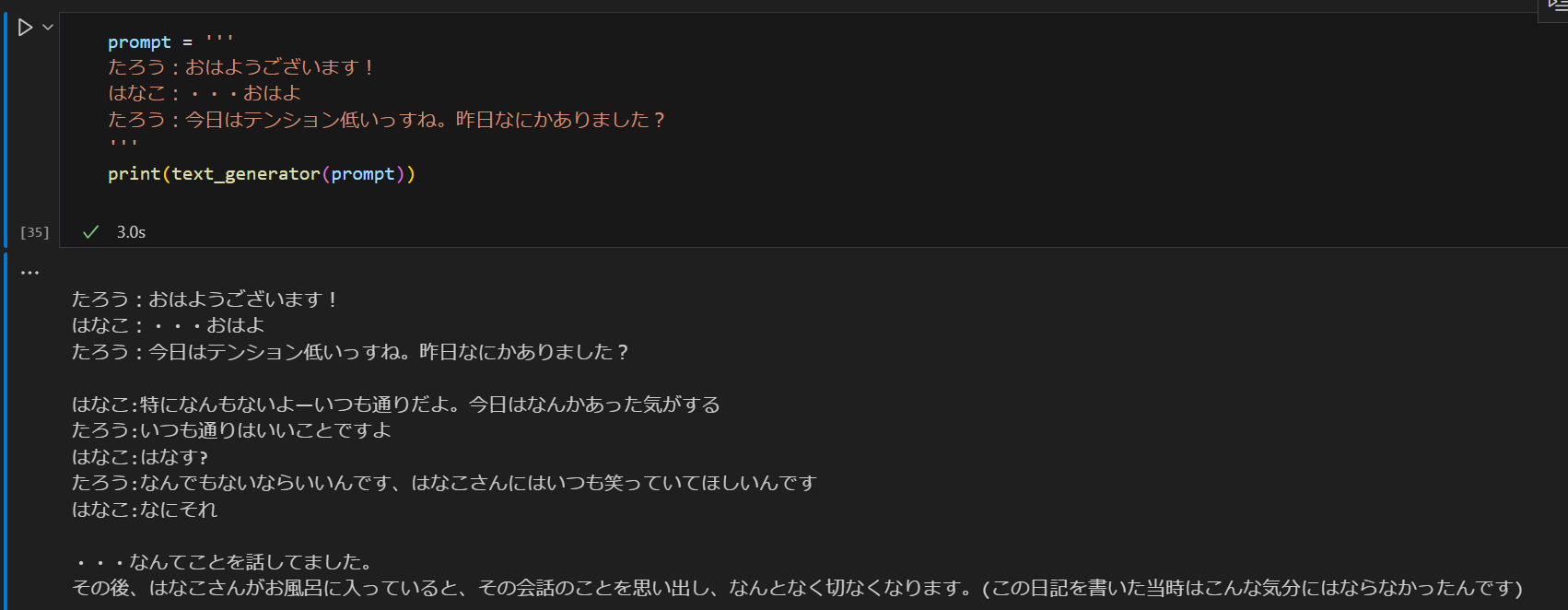
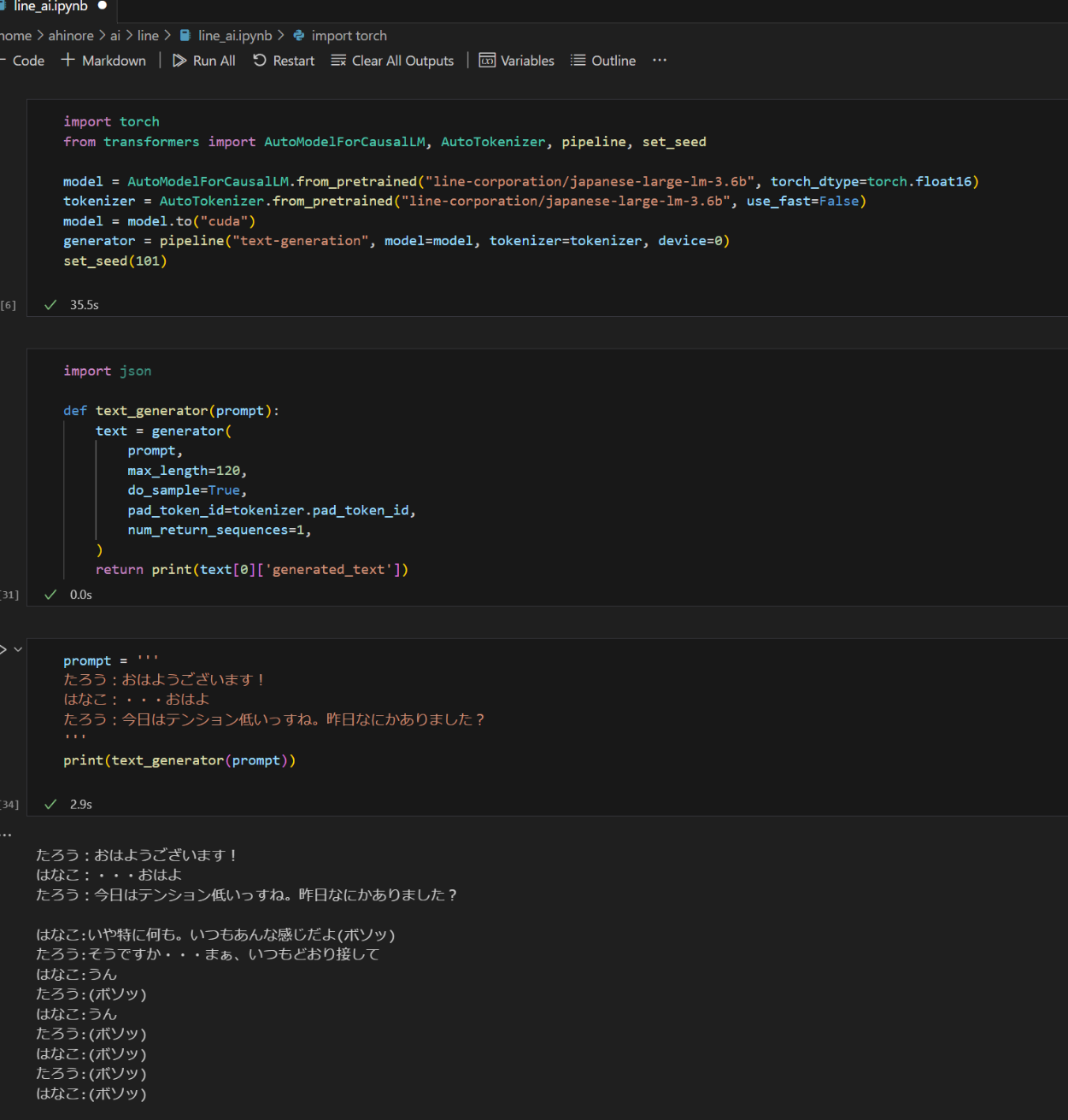
昨日公開されたLINEのLLMに今日の同僚との会話の冒頭を入れた所、ボソボソ言い出したw
結構自然な会話も出てくるので中々よさそうな感じ。
インストラクションチューニング版が楽しみ
https://engineering.linecorp.com/ja/blog/3.6-billion-parameter-japanese-language-model
家鴨
さんがブースト

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
@ahinore 言及ありがとうございます。LINEのメッセージはクライアント間で暗号化されてますし、オープンチャットのデータは暗号化されてませんがLLM構築に使われることに嫌悪感を覚えるお客様がいらっしゃいますので、「気持ち悪いことはしない」の法則に従って利用しない選択をしています。結構性能良いので使えるかどうかお試しください。
@overlast 中の方ですか!
素晴らしい言語モデルを公開頂き大変ありがたいです。しかもApacheライセンスで使いやすい。
コンテキスト読んで適切なLINEスタンプ返してくるAIとか面白そうですが、さすがに会話データの活用は難しそうですね〜
LINEのオプションで会話データの提供とか選択できれば喜んで提供しますがw
LINEからも日本語言語モデルが来た!
みんな気になるLINEの会話データは学習に使ってない模様。使ってたら面白いのに
https://engineering.linecorp.com/ja/blog/3.6-billion-parameter-japanese-language-model
{kind=link}
{kind=link}
同僚は店長がワンオペだと肉の量減るって言ってたので人の問題かもしれない。
バイトはそんなの気にしないし
確か昔吉野家の特番で作業量と機材減らすために特盛は並の肉を2回入れるって言ってたので、コレは店舗が不正をしているような気がする
吉野家の大盛り、うちの近くの店舗だと明らかに肉の量増えてるんだけど、コレは店舗の問題では、、、
https://www.syokuraku-web.com/column/110969/2/
昔の記事だと大盛りの方が量多いので、もしかすると昨今の値上げブームで減ったのかもしれないが真相はいかに
https://menucoupon.net/yoshinoyasize
{kind=link}
2017年 4月 に登録
