

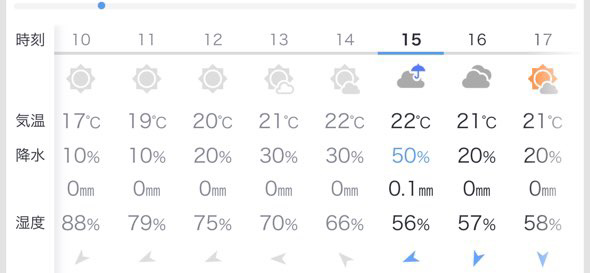
朝Yahoo天気の予報が晴れのち曇りだったので、信じて洗濯物干してきたのに土砂降り、、、
騙された!と思って見返したら、15時だけ雨になって今日の天気も変わってる、、、😣
{kind=link}
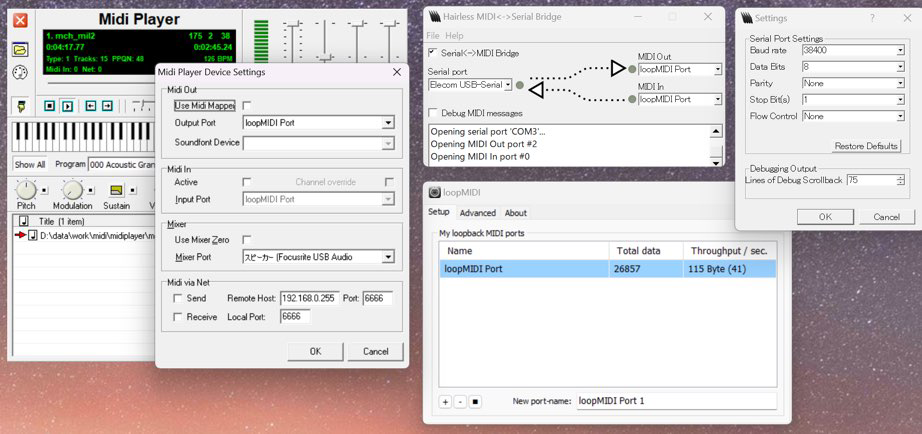
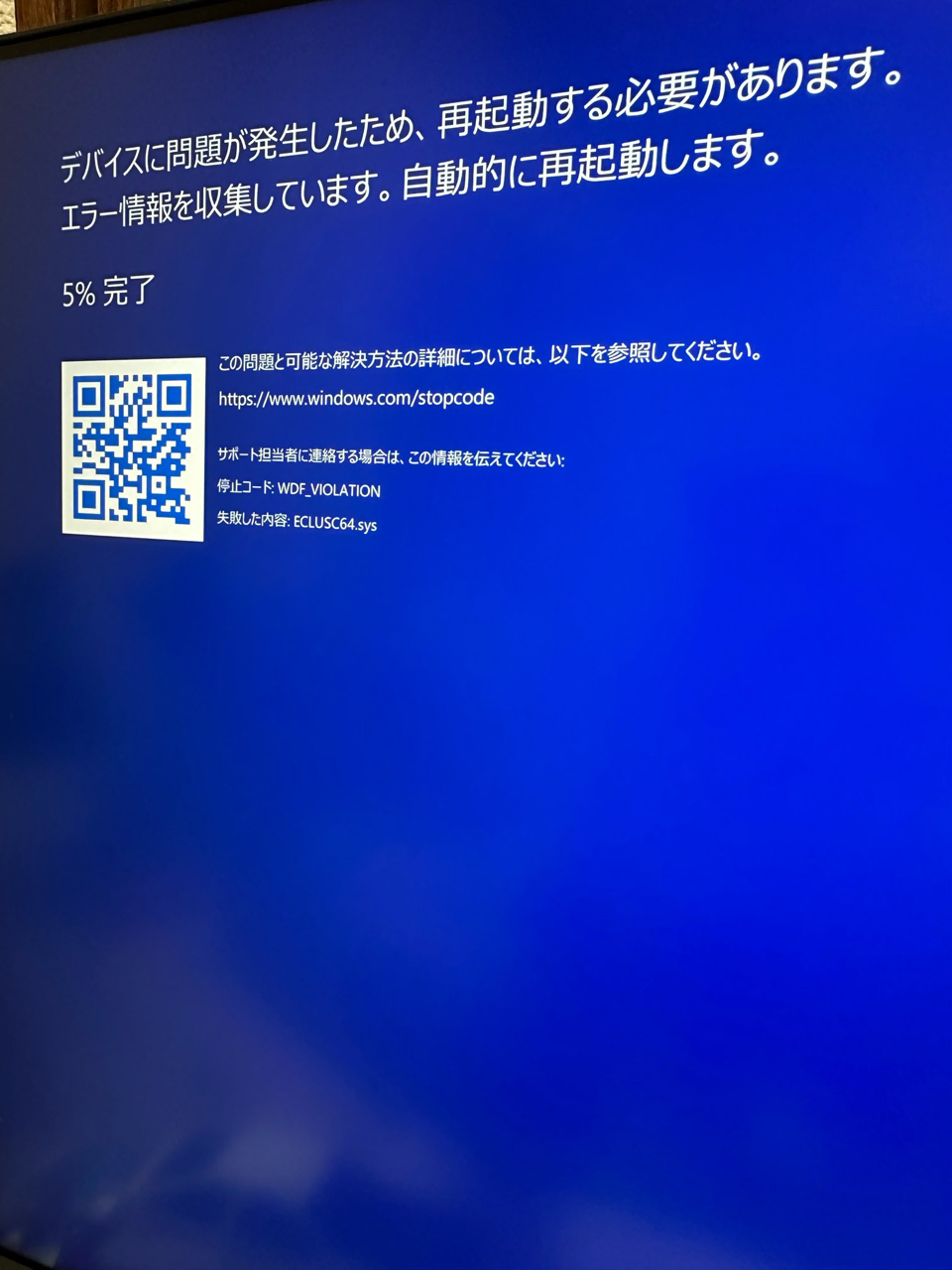
SC88をシリアルUSBケーブル経由で駆動できないかなぁと色々模索した所、下記仮想ポートソフトとMidi Playerを組み合わせたら動いた!
・loopMIDI
・Hairless MIDI
でもずっと演奏してたらブルースクリーンに😱
素直にUSB-MIDIケーブル買えと言うことか
{kind=link}
{kind=link}
{kind=link}
{kind=link}
娘がギターやりたいと言うのでサイレントギター貸してあげてたら、数日でドレミとCコードが弾けるようになってた。子供は覚えるの早いなぁ。
とりあえず全力で褒めてたら、ボソっと「てか、ぼっちちゃん使ってるのエレキギターだよね、、、」と言われたw
まさかぼっちざロックの影響だったとは。
でもうちにあるエレキ、インギーモデルとジョンペトルーシモデルなんだよね、、、
もう一本普通の買うべきかな
メタンハイドレートとレアアースは外国が資源を出し渋る際に必ず国内生産のニュースが出てくるけど、中々本格化しないなぁ。
単に海外牽制してるだけなのかな
https://news.tv-aichi.co.jp/single.php?id=1532
もう50年か。
https://news.yahoo.co.jp/articles/262e7b221edfcdd17143f67b2265aae785fcb470
昔日本在住のアメリカ人が、子供がチューバッカの番組好きで観てるって言ってて謎だったけど、後でムックだったと判明した時は笑ったなぁ。
色とか全然違うけど毛深さは似てる。
アシュリー役の人、RE4発売に合わせて髪型同じにしてるのが良い
https://twitter.com/Eriza_Freya/status/1639069345727782912?s=20
バイオハザード:RE4のアシュリーとアシュリー役の人が同時に映ってる貴重映像
https://twitter.com/Eriza_Freya/status/1646149989691797506?s=20
RWKVの14億パラメータモデルで2%ほど日本語がトレーニングデータに入ってる物があったので試したところ、内容は変だけど一応受け答えはできるようになってる。
https://huggingface.co/BlinkDL/rwkv-4-raven
日本語データをもっと入れたモデル、どっかの研究機関が作ってくれないかなぁ。リソース的に個人じゃ無理、、、
{kind=link}
地震速報並みに怖い音量
{kind=link}
VRChatをSLI的にブーストしたかったのではなく、キャプチャと動画エンコードを別GPUにオフロードしたかったのでは。
VRChatだけなら3090で十分だし。
今回の問題はVRChat起動するとバーチャルデスクトップもエンコードも3090使うようになっちゃう点で、VRChatがSLI対応してないとかは関係ないかと。
小学生の娘がギターやりたいと言い始めた!
ピアノは途中で辞めちゃったので、ギターは何とか褒めまくって続けさせたいなぁ。
何とか飽きずに最初の壁を乗り越えられるような練習方法はないだろうか。
そりゃやる人出るよね〜
https://gigazine.net/news/20230410-samsung-chatgpt-security-leak/
GitHubに機密情報あげる人もいるし、コレはツールどうこうという話では無く根本的な教育の話な気がする。
でもまぁ会社としては規制する方向になっちゃううんだろうなぁ
サイバーパンク2077のパストレーシングパッチが来たので試してみた所、淡い光の表現力がかなり上がっている気がする。
普通のレイトレだと完全に暗くなってしまう所が、パストレだと反射光が来て少し明るくなってる。
でもGPUが全力出してくるので足元が熱い、、、
{kind=link}
{kind=link}
いつの間にかTwitter無くなってたのか
「機械学習エンジニアのためのTransformers」読了。
わからない所は流し読みしつつ読んだけど、概要は理解できた気がする。
https://www.oreilly.co.jp/books/9784873119953/
魔法のように見えるGPTも仕組みとしては単純で、単語間のつながりをいろんな観点(文法とか文脈とか)で学習させ、そのモデルを使って入力された単語の次に来る確率が高い単語を出力してるだけだった。
文法とか文脈の観点(マルチヘッドアテンション)は明示的に教えるのではなく、大量のデータを学習する過程で自動で獲得するのホント面白い。
レトルト版じゃないボンディ、ふるさと納税とか通販で買えたのか!
http://bondy.co.jp/order.cgi
{kind=link}
Transformerについて勉強しててマルチヘッドアテンションがよくわからんのでGPT4に説明求めたら専門的な解説が始まったので、小学生でもわかるように教えてって聞いたらほんとに小学生でもわかるように例え話出してきた、、、
鳥肌立つ
{kind=link}
2017年 4月 に登録
